Amazon S3 (Simple Storage Service)
Amazon S3 — Main Features, Buckets and Objects, Use Cases

DevOps by profession because every developer needs Heroes :)
Amazon S3 is the most powerful and commonly used cloud storage service in AWS. By the end of the article, we will learn how Amazon S3 works and why we use Amazon S3.
What is Cloud Storage?
Before we learn Amazon S3, it's good to understand what Cloud Storage is. Cloud storage is a web service where users can store, access, and quickly back up data on the internet. It is more reliable, scalable, and secure than traditional on-premises storage systems.
What is Amazon S3 ?
Amazon S3 is a cloud storage service in AWS. Amazon S3 stands for Amazon Simple Storage Service. Amazon S3 is Object storage built to retrieve any amount of data from anywhere. Amazon S3 (Simple Storage Service) provides object storage, which is built for storing and recovering any amount of data from anywhere over the internet. S3 enables users to store and retrieve any amount of data at any time. So this gives developers access to highly scalable, reliable, fast, and inexpensive data storage.
Amazon S3 Core Concepts — Buckets and Objects
Organizing, storing, and retrieving data in Amazon S3 focuses on two key components:
- Buckets
- Objects that work together to create the storage system.
Buckets
A bucket is a container for objects stored in Amazon S3. In order to store your data in Amazon S3, you first create a bucket and specify a bucket name and AWS Region. Then, you upload your data to that bucket as objects in Amazon S3.
It’s also important to know that Amazon S3 buckets are globally unique. No other AWS account in the same region can have the same bucket names as yours unless you first delete your own buckets.
Objects
Objects are the fundamental entities stored in Amazon S3. Amazon S3 is an object storage service that stores data as objects within buckets. Objects are data files, including documents, photos, videos, and any metadata that describes the file. Each object has a key (or key name), which is the unique identifier for the object within the bucket.
Objects consist of object data and metadata. The metadata is a set of name-value pairs that describe the object. These pairs include some default metadata, such as the date last modified, and standard HTTP metadata, such as Content-Type. We can also specify custom metadata at the time that the object is stored.
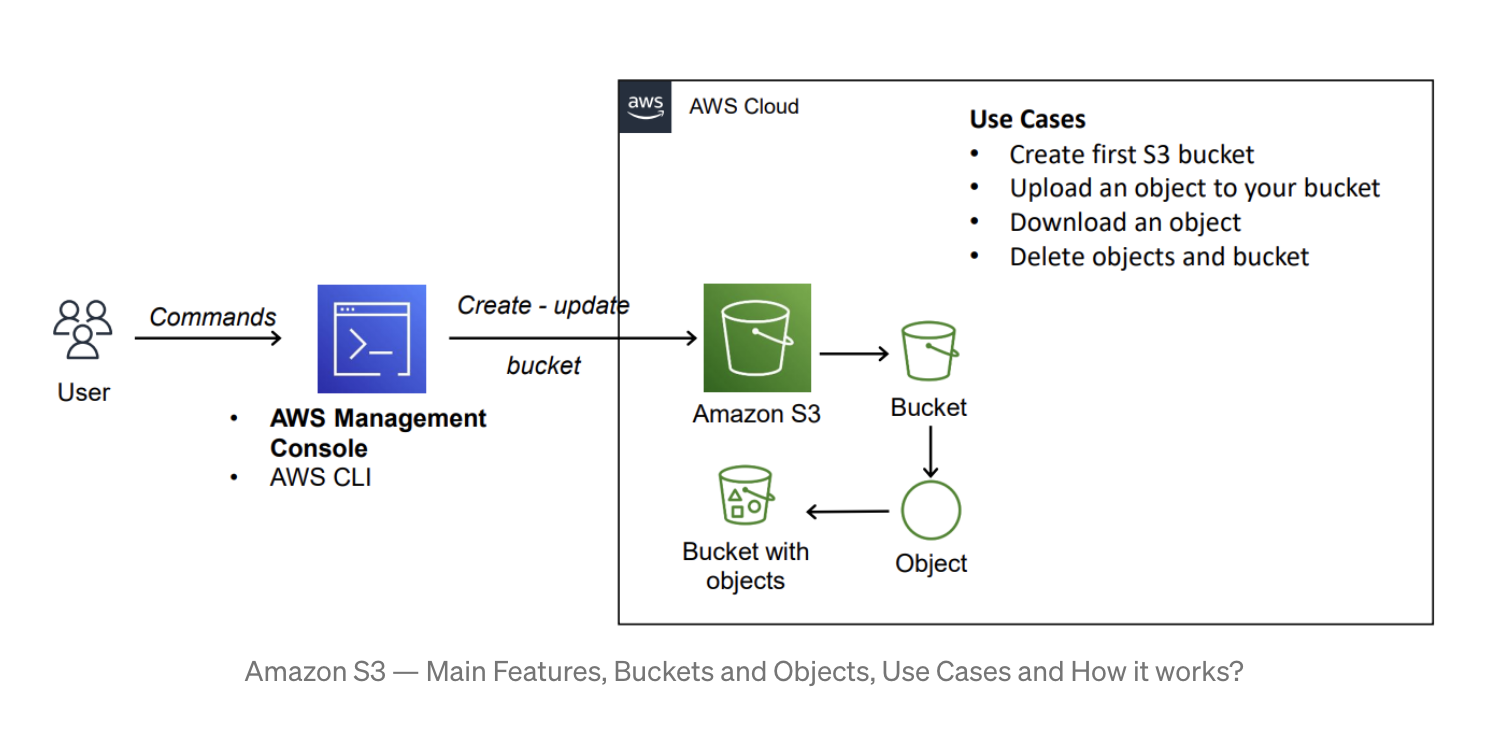
How Amazon S3 Work ?
When we create a bucket, we should give a bucket name and choose the AWS Region where the bucket will reside. After we create a bucket, we cannot change the name of the bucket or its Region.
It’s best practice to select a region that’s geographically closest to you. Objects that reside in a bucket within a specific region remain in that region unless you transfer the files somewhere else.
Amazon S3 Use Cases
Amazon S3 can be used in different use cases for managing objects into buckets for the company's business requirements.
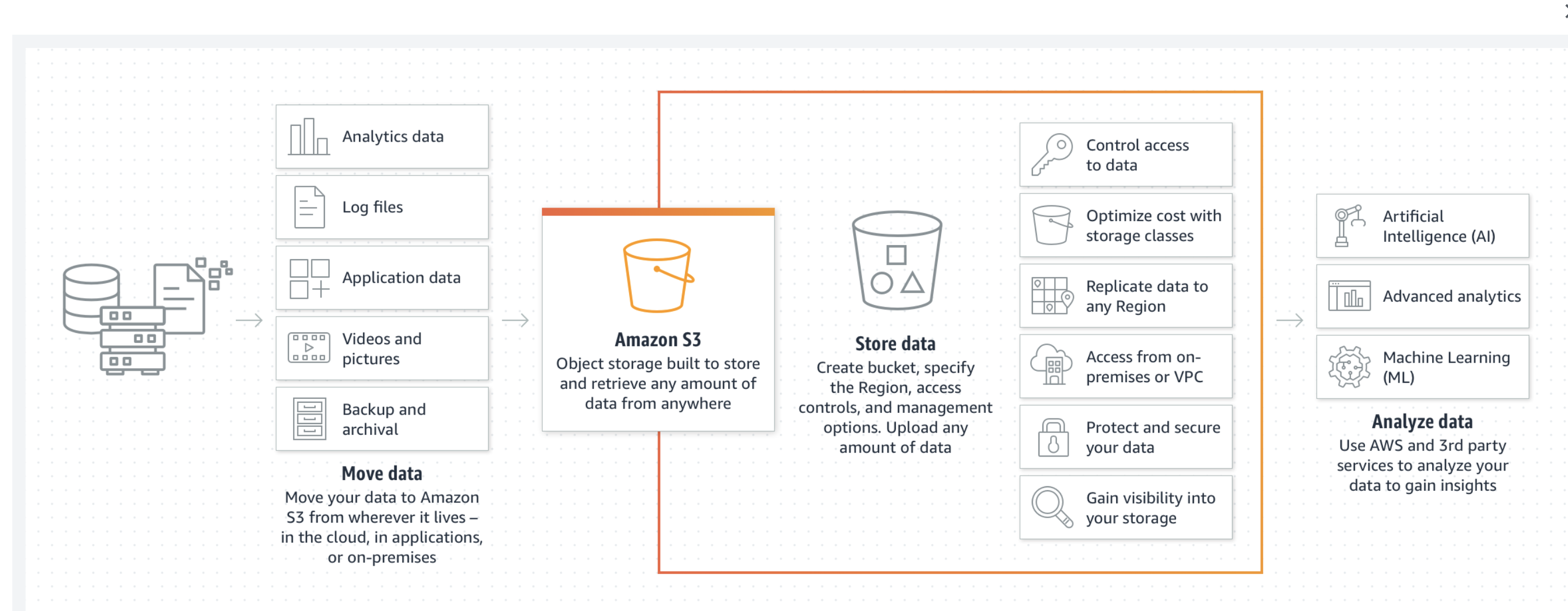
Amazon S3 has many use cases:
- Data Storage: S3 is ideal when you want to store application images and videos. All AWS services like Amazon Prime and Amazon.com, as well as Netflix and Airbnb, use Amazon S3 for this purpose.
- Backup and Disaster Recovery: Amazon S3 is suitable for storing and archiving critical data or backup data with its automatically replicated cross-region, providing maximum availability and durability.
- Analytics: We can run big data analytics, artificial intelligence (AI), and machine learning (ML) on Amazon S3.
- Data Archiving: We can move data archives to the Amazon S3 Glacier storage classes to lower costs, eliminate operational complexities, and gain new insights.
- Static Website Hosting: S3 stores various static objects. So that we can host SPA frontend layers using S3.
- Cloud-native applications: We can use microservices architectures for storing blob data and access from different services.
Thank you for reading I hope this blog helps you to understand the AWS S3 :)



